sequenceDiagram
actor Op as Opérateur
participant Dash as Dashboard
participant KB as Base de connaissances
participant ADO as Azure DevOps
Op->>Dash: Clic sur Ticket
Dash->>KB: Recherche pattern dans le message
KB-->>Dash: KB002 Timeout (priorité 3)
Dash->>Op: Modale avec KB match + priorité + assignation
Op->>Dash: Choisit priorité 2, assigne à Sylvain
Dash->>ADO: POST workitems/$Bug (priorité + assignee + KB info)
ADO-->>Dash: #37545 créé
Dash->>Op: Bouton vert #37545
Dans un article précédent, j’avais mis en place un puit de logs Azure avec un dashboard qui permettait de créer des tickets en un clic. Le POC fonctionnait : on voyait les logs, on cliquait, un Bug apparaissait dans Azure DevOps.
Mais à l’usage, deux manques sont apparus :
- Pas de mémoire : quand une erreur connue revenait, l’opérateur devait se souvenir de la résolution. Aucune capitalisation.
- Pas de contexte : le ticket était créé avec les infos du log, mais sans priorité, sans assignation, et sans lien avec les incidents précédents.
J’ai donc ajouté une base de connaissances et une modale de création de ticket enrichie.
Le problème : des erreurs connues qu’on redécouvre à chaque fois
Dans un contexte de monitoring, les mêmes erreurs reviennent. Timeout réseau, certificat expiré, disque plein. À chaque fois, quelqu’un passe du temps à diagnostiquer, trouve la résolution, corrige… et oublie de documenter. La prochaine occurrence, rebelote.
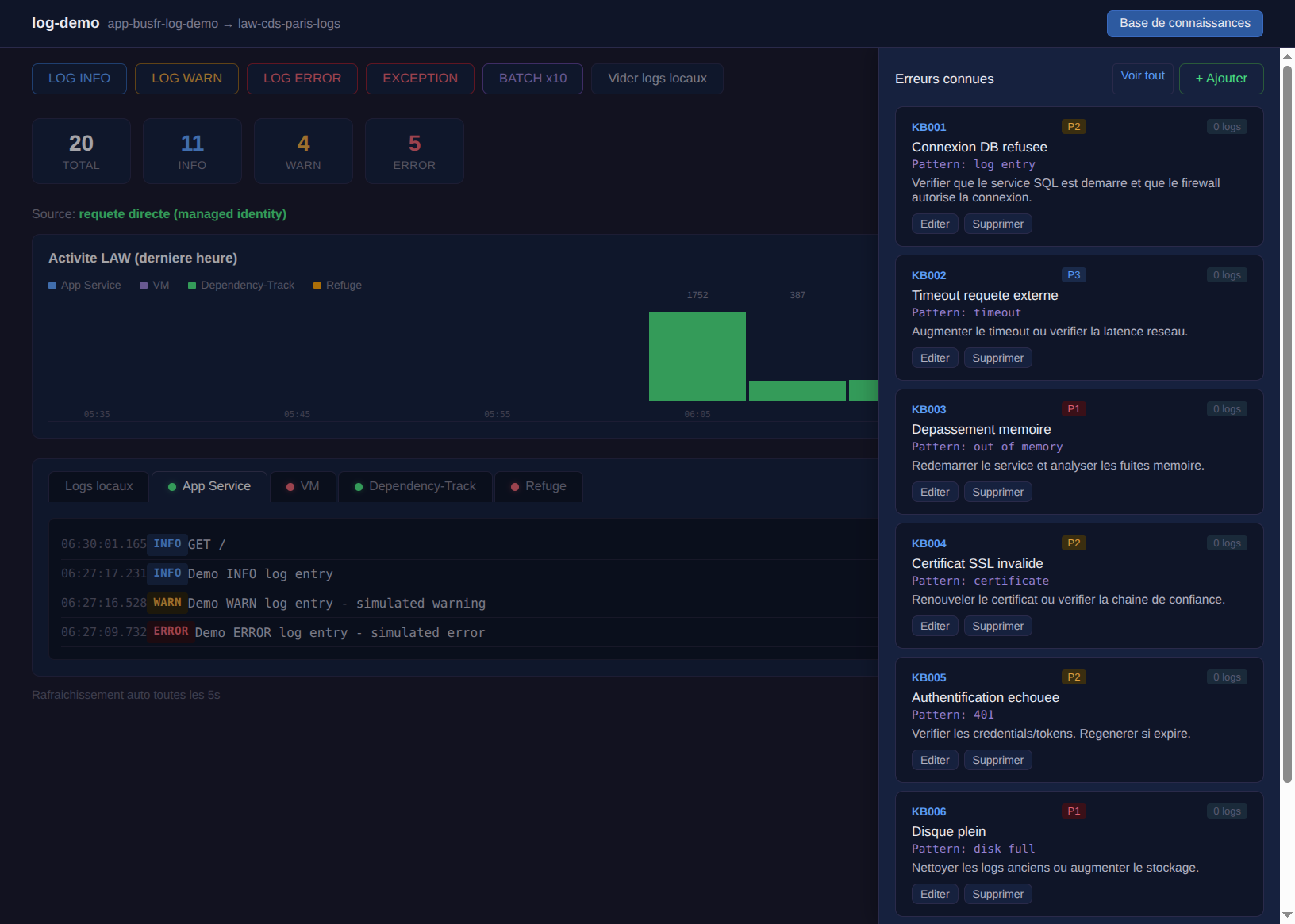
L’idée : quand on clique sur “Ticket” à côté d’un log d’erreur, le dashboard cherche automatiquement dans une base d’erreurs connues si le message matche un pattern. Si oui, il affiche la résolution suggérée et pré-remplit la priorité.
La modale : KB + priorité + assignation
Avant, le clic sur “Ticket” créait directement un Bug dans Azure DevOps. Maintenant il ouvre une modale :
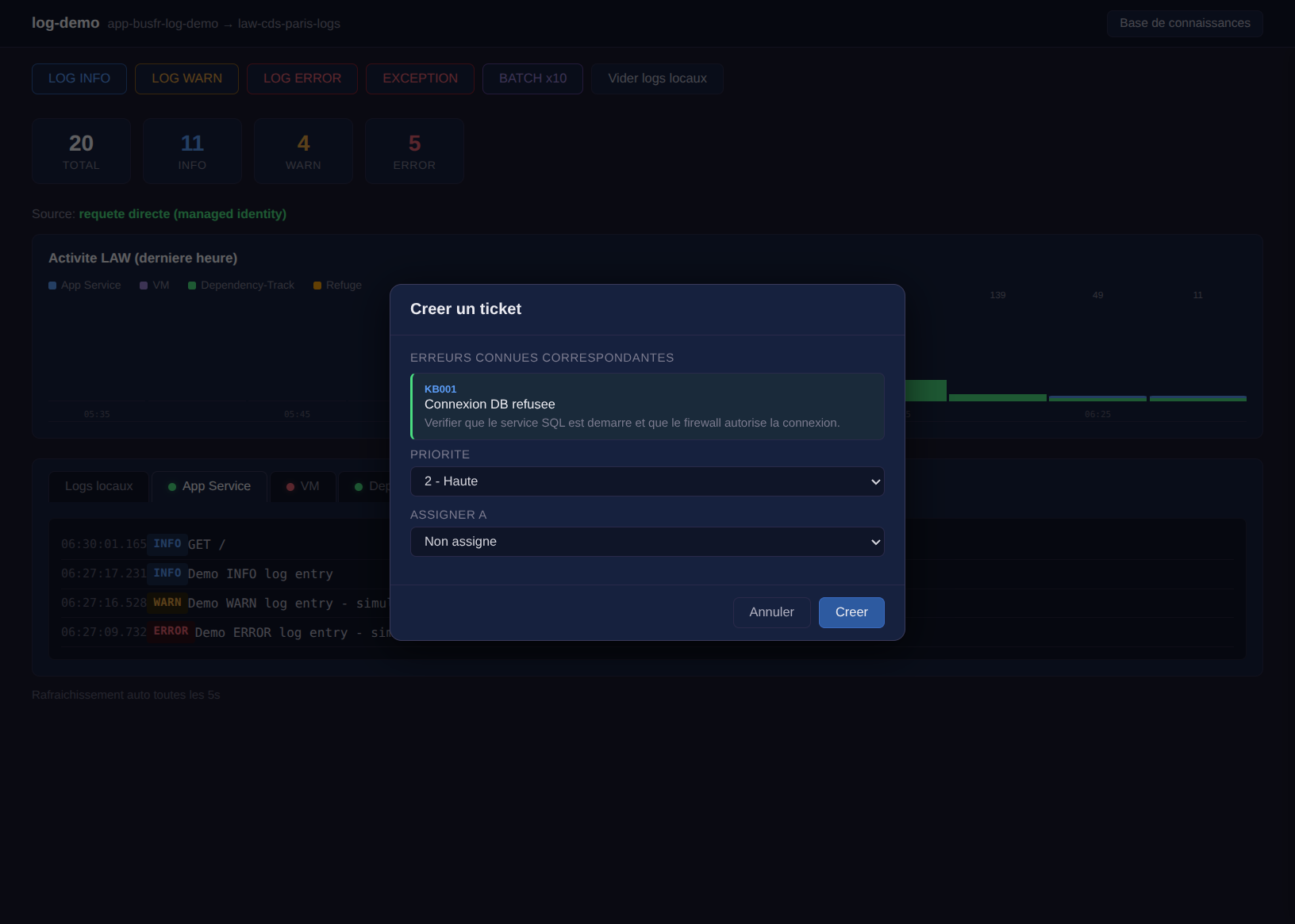
Ce qui se passe :
- Le message du log est comparé aux patterns de la base de connaissances
- Si un match est trouvé, l’erreur connue s’affiche avec sa résolution
- La priorité est pré-remplie (celle suggérée par la KB)
- On peut choisir à qui assigner le ticket
- Au clic sur “Créer”, le ticket part dans Azure DevOps avec toutes les infos
Quand une KB matche, sa résolution est aussi injectée dans le body du ticket Azure DevOps. L’opérateur qui ouvre le Work Item a directement la marche à suivre, sans chercher dans la doc.
La base de connaissances : CRUD simple, pas une usine
La KB est accessible de deux façons :
- Drawer latéral depuis la navbar du dashboard (accès rapide)
- Page pleine /kb avec pagination, recherche et édition
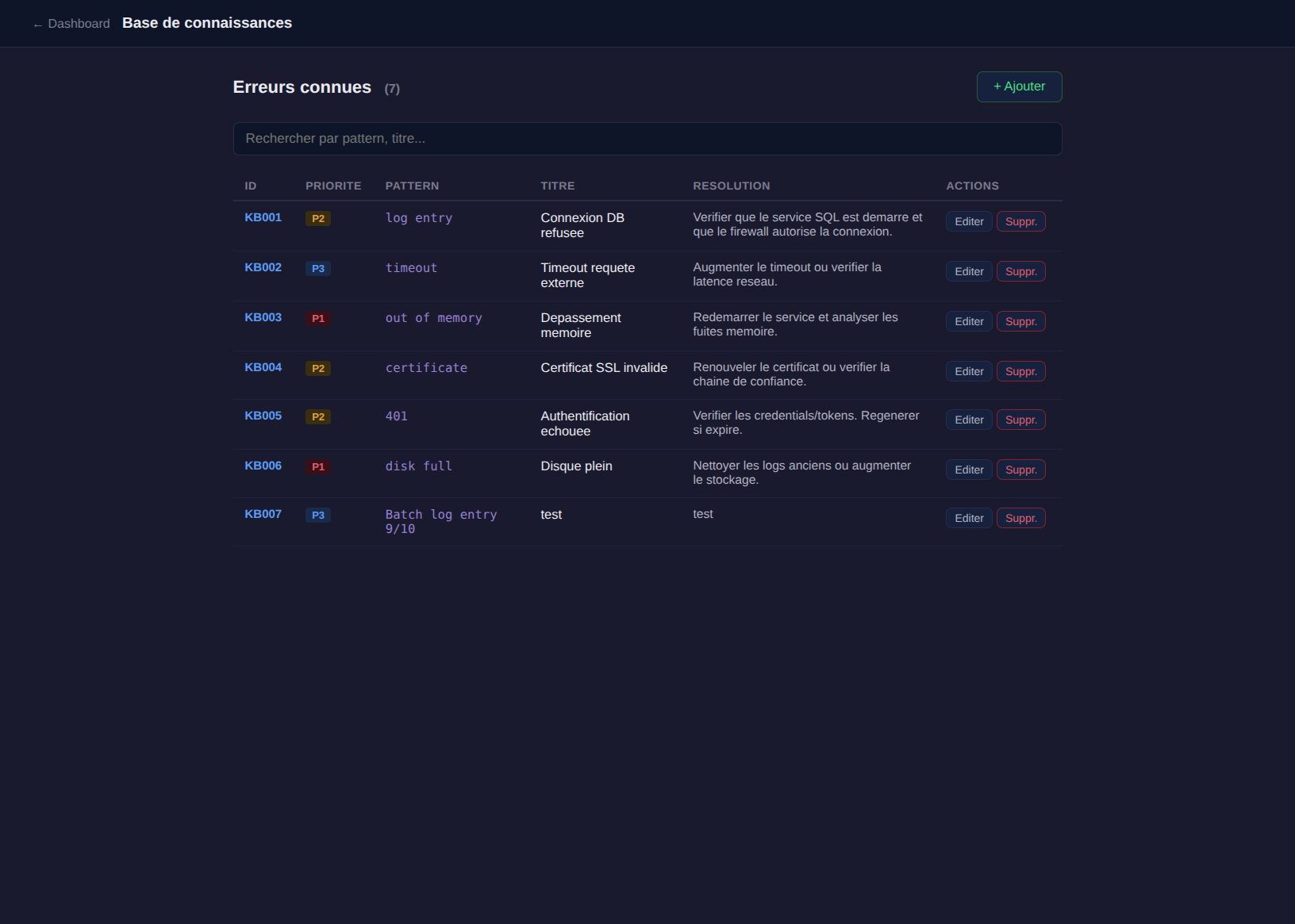
Chaque entrée a un pattern (mot-clé à matcher dans les messages de log), un titre, une résolution et une priorité suggérée.
Le stockage est un simple fichier JSON. Pas de base de données.
Pourquoi pas SQLite ?
J’ai d’abord implémenté la KB avec better-sqlite3. Ça marchait en local. Au déploiement sur App Service Linux, l’app a crash-loop : le module natif C++ compilé sur ma machine n’était pas compatible avec le conteneur Azure.
Le plan F1 (gratuit) a un quota CPU journalier. La crash-loop l’a consommé en quelques minutes. L’app s’est arrêtée, le Kudu SCM aussi, impossible de redéployer. J’ai dû scaler en B1 le temps de pousser le fix.
La leçon : sur App Service Linux, éviter les modules Node.js natifs (C/C++). Un fichier JSON avec fs.readFileSync/fs.writeFileSync fait le même travail pour une KB de quelques dizaines d’entrées, sans aucune dépendance native.
Le compteur de logs : quelle KB est “chaude” ?
Chaque carte KB dans le drawer affiche combien de logs LAW actuels matchent son pattern :
- Rouge : 5+ logs (problème actif)
- Orange : 1-4 logs (à surveiller)
- Gris : 0 logs (tout va bien)
C’est calculé côté client en croisant les patterns KB avec les logs LAW déjà chargés. Zéro requête supplémentaire.
Ça permet de voir d’un coup d’œil quelles erreurs connues sont actives en ce moment, et de prioriser.
La persistance du bouton ticket
Un détail UX qui a son importance : après création d’un ticket, le bouton passe de “Ticket” à “#37545” en vert. Le dashboard rafraîchit les logs toutes les 5 secondes, ce qui re-render le DOM entièrement.
Sans précaution, le bouton vert disparaît au prochain refresh. J’ai ajouté un cache en mémoire JS (_createdTickets) qui associe chaque log (source + timestamp + message) à son ticket. À chaque re-render, le cache est consulté et les boutons sont restaurés.
C’est éphémère (perdu au rechargement de la page), mais suffisant pour une session de monitoring.
Ce qui a cassé en route
| Problème | Impact | Résolution |
|---|---|---|
better-sqlite3 sur App Service Linux |
Crash-loop, quota F1 épuisé | Remplacé par JSON file storage |
| F1 quota exceeded | App et Kudu inaccessibles | Scale en B1 (~13€/mois) |
| Refresh DOM écrase le bouton ticket | Perte du feedback visuel | Cache _createdTickets en mémoire JS |
| KB en onglet à côté des sources | UX confuse | Déplacé dans la navbar (drawer latéral) |
Les chiffres
| Métrique | Valeur |
|---|---|
| Temps log -> ticket (avant) | ~2s, sans contexte |
| Temps log -> ticket (maintenant) | ~5s, avec KB + priorité + assignation |
| Entrées KB de démo | 6 erreurs connues |
| Dépendances natives ajoutées | 0 |
| Plan App Service | B1 Linux (~13€/mois) |
| Stockage KB | Fichier JSON (~1 Ko) |
Ce que j’en retiens
La capitalisation change tout
Sans KB, chaque erreur est traitée comme nouvelle. Avec, l’opérateur voit immédiatement “ah, c’est un timeout connu, voilà la résolution”. Le ticket part avec la bonne priorité et la bonne personne.
Le fichier JSON suffit pour un POC
Pas besoin de PostgreSQL ou Redis pour stocker 20 erreurs connues. Un fichier JSON lu/écrit avec fs fait le travail. Si la KB dépasse quelques centaines d’entrées, on migrera. En attendant, zéro config, zéro dépendance.
Les modules natifs Node.js et le PaaS ne font pas bon ménage
C’est la leçon la plus coûteuse de cette itération. Un npm install better-sqlite3 qui passe en local mais casse en production, ça peut bloquer un déploiement complet. Toujours vérifier la compatibilité avec l’environnement cible, ou privilégier les alternatives pure JS.
L’UX se découvre en testant
Le placement de la KB en onglet à côté des sources semblait logique en planification. En pratique, c’était confus : la KB n’est pas une source de logs. Le drawer latéral a été la bonne solution, trouvée en testant, pas en planifiant.
Suite du POC “puit de logs Azure”. Stack : Express.js, Azure App Service B1, Log Analytics Workspace, Azure DevOps. Février 2026.