flowchart TB
U[User] --> E[Environment]
E --> M[Model]
M --> ME[Memory]
M --> T[Tools]
ME --> M
T --> M
M --> E
Formation Udemy sur la création d’agents IA avec Python. Je documente ici ce que j’ai appris en suivant le cours Build Smart AI Agents 10x Faster.
Les 4 composants d’un agent IA
Tout agent IA repose sur 4 briques fondamentales :
| Composant | Rôle | Notre choix |
|---|---|---|
| Model | Comprend et raisonne | Ollama (llama3.2) / GPT-4o-mini |
| Memory | Se souvient du contexte | ChromaDB |
| Tools | Agit dans le monde réel | Google Books API, DuckDuckGo |
| Environment | Interface utilisateur | Streamlit |
Sans mémoire : “Montre-moi quelque chose de similaire” → “Similaire à quoi ?”
Avec mémoire : L’agent récupère le contexte et recommande intelligemment.
Sans outils : “Quel temps fait-il ?” → “Je ne peux pas savoir”
Avec outils : L’agent appelle une API météo et répond avec des données réelles.
Les 4 types d’agents IA
Le cours commence par une taxonomie des agents :
| Type | Principe | Limite |
|---|---|---|
| Réactif | SI ceci → FAIRE cela | Pas de mémoire |
| Proactif | Analyse → Planifie → Agit | Pas d’accès aux données live |
| Tool-Using | Raisonne → Choisit l’outil → Agit | Plus complexe à construire |
| Multi-Agent | Agents spécialisés qui collaborent | Overkill pour des cas simples |
Pour un agent de recommandation de livres, le choix est Tool-Using + Memory : il peut appeler des APIs (Google Books) tout en se souvenant du contexte via ChromaDB.
Architecture d’un système agentique
flowchart LR
A[User] --> B[UI]
B --> C[Model/LLM]
C --> D[Planner]
D --> E[Tool Router]
E --> F[APIs]
E --> G[Memory]
G --> C
F --> C
C --> B
| Composant | Rôle | Analogie |
|---|---|---|
| Model | Comprend et génère | Le cerveau |
| Planner | Décide et organise | Le manager |
| Tool Router | Exécute les actions | Les mains |
| Memory | Se souvient | La mémoire long-terme |
SQL vs Base vectorielle
C’est le concept clé pour la mémoire d’un agent.
SQL cherche des mots exacts :
SELECT * FROM users WHERE name = 'Mike'; -- ✅ Match exact
-- "Où j'habite?" vs "Ma ville est Paris" → ❌ Aucun matchChromaDB cherche le sens :
collection.query(query_texts=["Où j'habite ?"])
# Retourne "Ma ville est Paris" car le SENS est proche ✅Le texte est converti en embedding (liste de nombres représentant le sens). Deux phrases avec la même idée auront des embeddings proches, même si les mots sont différents.
Ce que j’ai construit
Un AI Book Finder Agent : un agent conversationnel qui recommande des livres en utilisant l’API Google Books, avec mémoire persistante via ChromaDB.
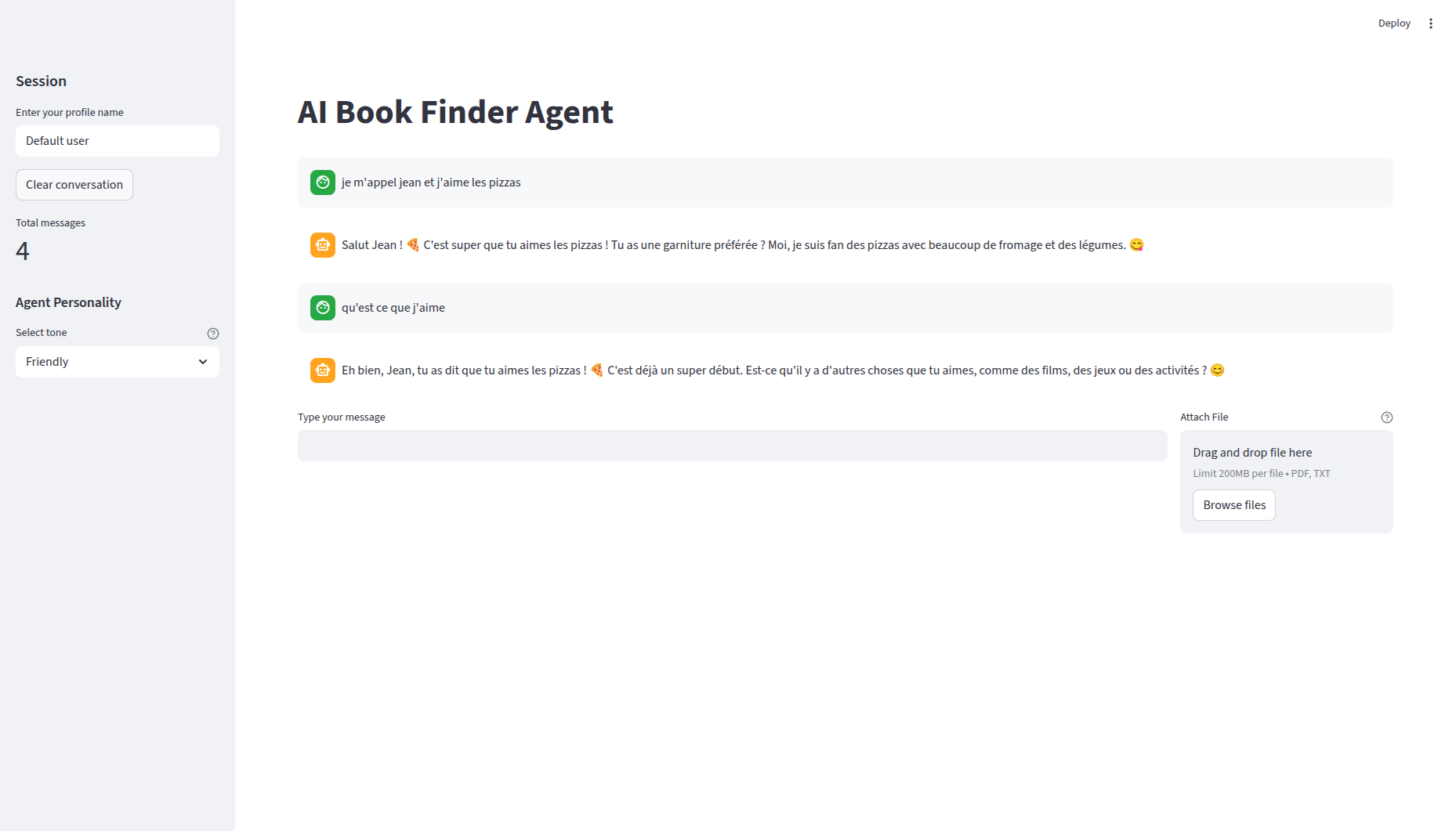
Stack technique
| Composant | Rôle |
|---|---|
| Ollama (llama3.2) | LLM local pour l’inférence |
| ChromaDB | Base vectorielle pour la mémoire |
| LangChain | Orchestration des prompts et chaînes |
| Streamlit | Interface utilisateur |
| Google Books API | Source de données livres |
Architecture de l’agent
flowchart TD
A[Message utilisateur] --> B[extract_intent]
B --> C[planner_decide_tools]
C --> D[extract_topic_from_query]
D --> E[Google Books API]
E --> F[store_to_memory]
F --> G[format_recommendations]
G --> H[Réponse Markdown]
Concepts clés appris
1. Extraction de topic avec LLM
Avant d’appeler l’API, le LLM extrait le sujet principal en 1-4 mots :
def extract_topic_from_query(user_message):
prompt = f"""
Extract only the main topic from this query.
Return 1-4 words only.
Query: "{user_message}"
"""
response = chat(model="llama3.2", messages=[{"role": "user", "content": prompt}])
return response["message"]["content"].strip()Exemple : “I want books about improving my daily habits” → “daily habits”
2. Chaînes LangChain avec RunnableLambda
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda
intent_chain = RunnableLambda(
lambda msg: intent_prompt.format(user_message=msg)
) | RunnableLambda(
lambda prompt: call_ollama_direct(prompt)
)3. Mémoire vectorielle avec ChromaDB
from chromadb import PersistentClient
client = PersistentClient(path=".chroma_db")
collection = client.get_or_create_collection(name="book_memory")
# Stockage avec embeddings automatiques
collection.add(
documents=["Atomic Habits - James Clear - ..."],
metadatas=[{"title": "Atomic Habits", "author": "James Clear"}],
ids=["book_1"]
)
# Recherche sémantique
results = collection.query(query_texts=["books about habits"], n_results=3)4. Persistance du chat
Chaque message est sauvegardé avec un timestamp pour reconstruction de l’historique :
def save_chat_message(collection, role, text, user_id):
collection.add(
documents=[text],
metadatas={"role": role, "ts": time.time(), "source": "chat", "user_id": user_id},
ids=[f"chat_{user_id}_{int(time.time()*1000)}"]
)Structure du projet
build-smart-ai-agents-2026/
├── ai_agent.py # Logique agent (LLM, API, mémoire)
├── app.py # Interface Streamlit
├── requirements.txt
└── docs/
└── learn/ # Notes d'apprentissage datées
├── 2026-01-25_2240_openlibrary-api.md
├── 2026-01-25_2300_ollama-integration.md
├── 2026-01-25_2315_langchain-chains.md
└── ...Points forts de la formation
- Approche progressive : chaque fonction est expliquée avant d’être intégrée
- Code fonctionnel à chaque étape
- Utilisation d’Ollama pour rester 100% local (pas de clé API OpenAI requise)
- Concepts RAG (Retrieval Augmented Generation) appliqués concrètement
Section 8 : Agent avancé
Agent Internet avec DuckDuckGo
L’agent Book Finder est limité aux livres. La Section 8 introduit un agent généraliste capable de chercher sur le web :
from langgraph.prebuilt import create_react_agent
from langchain_ollama import ChatOllama
from langchain_community.tools import DuckDuckGoSearchRun
def run_internet_agent(user_message):
search_tool = DuckDuckGoSearchRun()
llm = ChatOllama(model="llama3.2", temperature=0.1)
agent_executor = create_react_agent(llm, [search_tool], prompt=SYSTEM_INSTRUCTION)
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content=user_message)]},
stream_mode="values"
):
# Le LLM décide quand chercher sur le web
...| Aspect | Book Agent | Internet Agent |
|---|---|---|
| Source | Google Books API | DuckDuckGo |
| Décision | Toujours chercher | LLM décide quand chercher |
| Tool Calling | Non | Oui (llama3.2) |
Upload de fichiers PDF/TXT
import PyPDF2
def extract_text_from_pdf(uploaded_file):
pdf_reader = PyPDF2.PdfReader(uploaded_file)
return "\n".join([page.extract_text() for page in pdf_reader.pages])Le contenu du fichier est injecté dans le prompt système. L’utilisateur peut poser plusieurs questions sur le même fichier.
Section 9 : LangGraph - Du chaos au contrôle
Le problème de la boîte noire
Jusqu’ici, l’agent fonctionne mais on ne sait pas comment il prend ses décisions :
Agent traditionnel = BOÎTE NOIRE
Question → [???] → Réponse
↑
On ne sait pas ce qui se passeLangGraph : des graphes explicites
LangGraph transforme l’agent en un workflow visible avec des nœuds et des connexions conditionnelles.
flowchart TD
A[START] --> B[Analyze Node]
B --> C[Generate Node]
C --> D[Validate Node]
D --> E{Réponse OK?}
E -->|Non| F[Refine Node]
F --> D
E -->|Oui| G[END]
Les 3 concepts clés
| Concept | Rôle |
|---|---|
| State | Données qui circulent (query, response, file_data…) |
| Nodes | Fonctions qui traitent l’état |
| Edges | Connexions entre nœuds (peuvent être conditionnelles) |
Implémentation
from langgraph.graph import StateGraph, END
from typing import TypedDict
class AgentState(TypedDict):
user_message: str
decision: str # analyze_file, web_search, direct_answer
response: str
needs_refinement: bool
attempt_count: int # Évite boucle infinie
def create_agent_graph():
workflow = StateGraph(AgentState)
workflow.add_node("analyze", analyze_query_node)
workflow.add_node("generate", generate_response_node)
workflow.add_node("validate", validate_response_node)
workflow.add_node("refine", refine_response_node)
workflow.set_entry_point("analyze")
workflow.add_edge("analyze", "generate")
workflow.add_edge("generate", "validate")
# Edge conditionnel : raffiner si réponse trop courte
workflow.add_conditional_edges(
"validate",
should_refine,
{"refine": "refine", "end": END}
)
workflow.add_edge("refine", "validate") # Boucle
return workflow.compile()Ce qui rend l’agent “agentique”
- Raisonnement explicite : On voit quelle décision a été prise
- Auto-validation : Vérifie que la réponse est suffisante (> 30 chars)
- Auto-correction : Boucle de refinement si nécessaire
- Contrôle : Max 2 tentatives pour éviter boucle infinie
| Aspect | Avant | Après (LangGraph) |
|---|---|---|
| Décision | if/else imbriqués | Node dédié |
| Validation | Aucune | Node validate |
| Auto-correction | Non | Boucle refine |
| Débuggabilité | Difficile | Chaque node visible |
Bilan
Ce cours couvre bien les fondamentaux de l’IA agentique :
- RAG : Retrieval Augmented Generation avec ChromaDB
- Tool Calling : Le LLM décide quand utiliser des outils
- Mémoire : Reconstruction du contexte à chaque appel
- LangGraph : Workflow explicite avec auto-correction
Le passage de “boîte noire” à “graphe contrôlable” est le concept le plus important pour construire des agents fiables en production.

Comment fonctionne la mémoire
Les API LLM sont stateless : chaque appel est indépendant. La solution ? Stocker TOUT dans ChromaDB et reconstruire le contexte à chaque appel.
Point clé : Le système ne “comprend” pas que Jean est un nom. Il stocke le texte brut. C’est le LLM qui est intelligent : il extrait les infos du contexte.